Overview
The Shift from Prompting to Engineering
The honeymoon phase of "prompt engineering" is ending. For staff engineers, the challenge has shifted from getting a "cool" response to building deterministic, scalable, and secure AI middleware. Transitioning a wrapper into a production-grade system requires a rigorous focus on architecture over syntax.
1. The RAG Evolution: Beyond Basic Vector Search
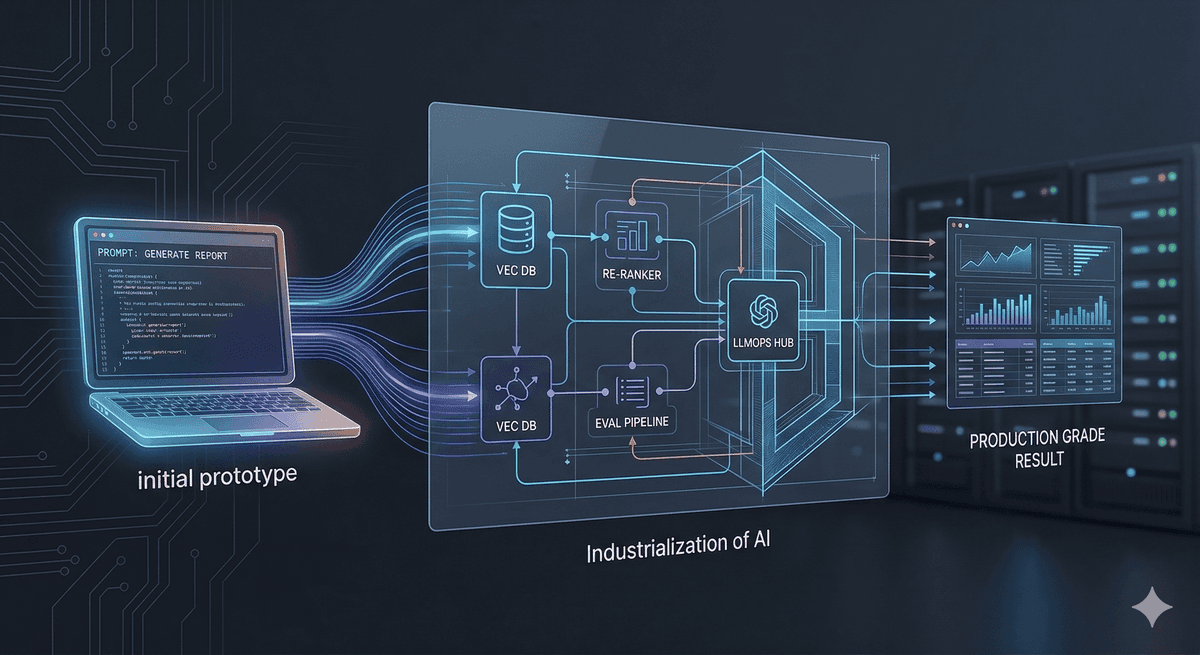
Standard Retrieval-Augmented Generation (RAG) often fails in production due to "noise" in the retrieval step. To solve this, we move toward Agentic RAG:
Query Transformation: Using a "Reasoning" step to rewrite vague user queries into optimized search terms.
Re-ranking: Implementing a Cross-Encoder model after the initial vector search to ensure the top $K$ results are actually relevant.
Hybrid Search: Combining Vector (semantic) search with BM25 (keyword) search to handle technical jargon and specific IDs.
2. Guardrails and Determinism
LLMs are inherently stochastic. In a production School ERP or Payroll system, hallucinations are critical failures.
Output Parsing: Use libraries like Pydantic or Zod to enforce strict JSON schemas.
Validation Layers: Implement a "Critic" pattern where a smaller, faster model (like GPT-4o-mini or Claude Haiku) validates the output of the primary model against business logic.
3. Observability and LLMOps
You cannot manage what you cannot measure. Production AI requires specific telemetry:
Token Usage Tracking: Monitoring costs per user/request.
Latency Tracing: Identifying if the bottleneck is the embedding generation, the vector DB lookup, or the LLM inference.
Evaluation (Eval) Pipelines: Running "Golden Datasets" against your system every time you update the prompt or the model version to prevent regression.
Note: Always implement a circuit breaker pattern for your AI API calls. If the provider (OpenAI/Anthropic) has a 503 outage, your core application logic must remain functional.